



手話習得が困難な要因の一つ「習得すべき手話単語の多さ」
大阪公立大学は、米国の手話単語のAIを用いた認識手法について、従来の認識手法に手や顔の表情などの「局所情報」と手と体の位置関係を表す「骨格情報」を加えた認識手法を開発したと発表しました。
画像はリリースより
手話は、聴覚障がいがある当事者とコミュニケーションを取る方法の一つです。手や腕の動き、表情、手の形状、手と体の位置関係などの情報を組み合わせることで表現される単語(手話単語)を、さらに組み合わせることで会話を実現する視覚言語の一種です。世界各国独自の手話が体系化されており、どの国の手話も数千個以上の手話単語が存在しています。手話の習得を難しくしている要因の一つに、習得すべき手話単語の多さがあると考えられています。
大まかな動きのみで、手話単語の高精度認識は不可
そのため、手話単語を表現する話者を撮影した動画から、AIを用いて手話単語を自動で認識する研究が行われています。これまでの手話単語認識に関する研究では、手話を一般的な動作の一種(例:お辞儀をする、手を振る、など)と見なし、話者の大まかな動きの情報を捉える手法を用いてきました。しかし、実際の手話では、「手の形の細かな違い」や「手と体の位置関係の違い」によって意味が異なります。そのため、大まかな動きの情報だけでは、手話単語を高精度に認識できないという問題がありました。
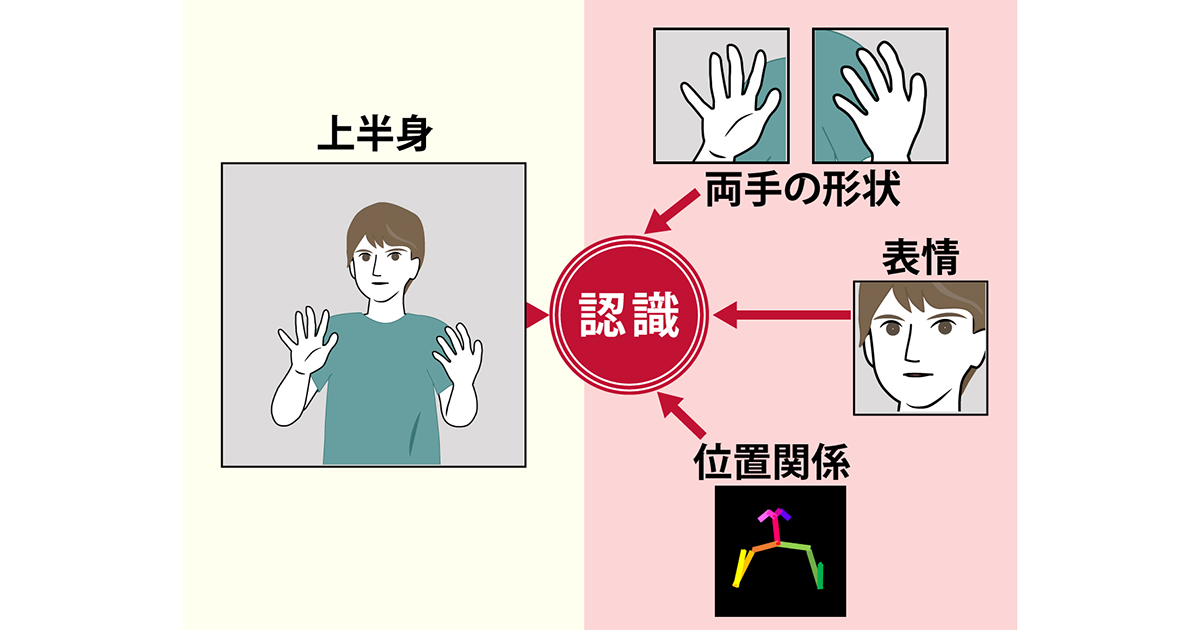
話者の上半身の大まかな動き+顔の表情など局所情報+人物の骨格情報で、高精度認識
研究グループは今回、手話を表現している話者の上半身の大まかな動きの情報に、手や顔の表情などの「局所情報」と、手と体の位置関係としての「人物の骨格情報」を加えることで、手話単語の認識精度を向上できるのではないかと考えました。これを実現するために、上半身と局所領域の情報には深層学習モデルI3D、骨格情報にはST-GCNを用いて、情報ごとに手話単語を認識した結果を統合しました。米国の手話単語認識データセットで検証した結果、話者の大まかな動きの情報のみを用いた従来手法と比較して、認識精度を10~15%向上できることがわかりました。
今回の研究によって、手話単語認識の精度を高めることができました。また、今回提案した手法は、どの国の手話にも適用できます。そのため、さまざまな国において、聴覚障がいがある当事者のコミュニケーション活性化が期待されます。研究グループは今後、手話単語認識のさらなる精度向上や、同手法を用いた手話翻訳の構築と精度向上などの課題解決を目指します。(遺伝性疾患プラス編集部)




